后端开发配置全过程(Java安装及环境配置,IDEA安装,MySQL和Navicat安装,IDEA中使用MySQL)
本文共 3197 字,大约阅读时间需要 10 分钟。
前言: 后端开发配置全过程:Java安装及环境配置,IDEA安装,MySQL和Navicat安装,IDEA中使用MySQL。
开始写后端,发现资料都是零零散散的,以下是我亲身实践过的方法汇总,希望对大家后端开发有所帮助。
1.安装Java并配置环境变量
2.安装IDEA
推荐安装JetBrains Toolbox (还可以申请学生免费授权计划)
安装IDEA时,注意看好版本,不要安装Community(Community中无法连接数据库),我安装的是 Ultimate,没有尝试其他版本,不知道其他版本是否可以连接数据库。3.安装MySQL
个人建议:最好不要改变MySQL安装位置。我尝试改变安装位置以后,发现无法找到“MySQL\MySQL Server”,无法配置环境变量。
4.安装Navicat for MySQL
3、4步骤做完以后:打开Navicat—>连接—>“MySQL…”—>输入连接名和安装MySQL时的密码
注意:在Navicat上打开MySQL之后显示的是服务器,需要自己创建数据库。创建数据库有两种办法:1.右键--->创建数据库...;2.使用SQL语句创建数据库
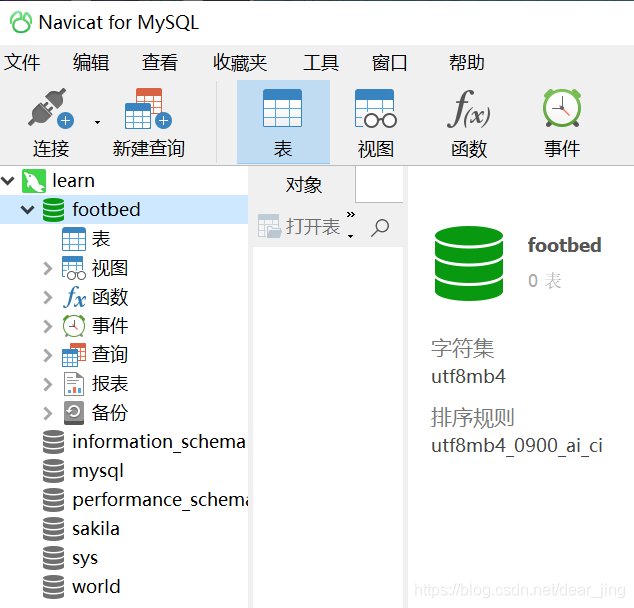
下面是我用Navicat打开MySQL后显示结果,learn是服务器;我在learn下面又建了一个数据库footbed;建完数据库以后要打开数据库(显示绿色就是已经打开了,灰色就是还没打开);其余那些是自带的数据库。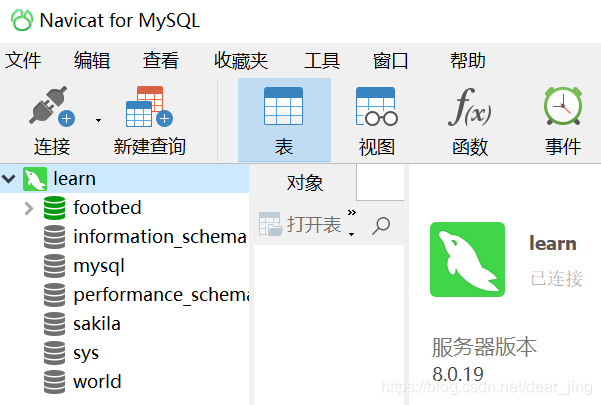
5.IDEA连接MySQL
使用过eclipse的小伙伴都知道,eclipse要能连接数据库,不仅电脑上要安装SQL Server、MySQL等数据库,还要安装相应的JDBC。IDEA连接数据库同样需要以上两个步骤(3、4已经完成了第一个步骤,接下来是第二个步骤):
1)“Server returns invalid timezone. Go to 'Advanced' tab and set 'serverTimezon”错误: 2)下载驱动包 : 3) 注意: 1.导入包时不要导入.zip压缩包,会显示“Empty Libraries”。如果是zip压缩包,解压缩以后再导入应该会成功;如果是.jar,直接导入就好。 2.第5步点击ok后,返回到如下图所示页面,需要先点"apply",再点"ok"。才会出现如链接中6所示。 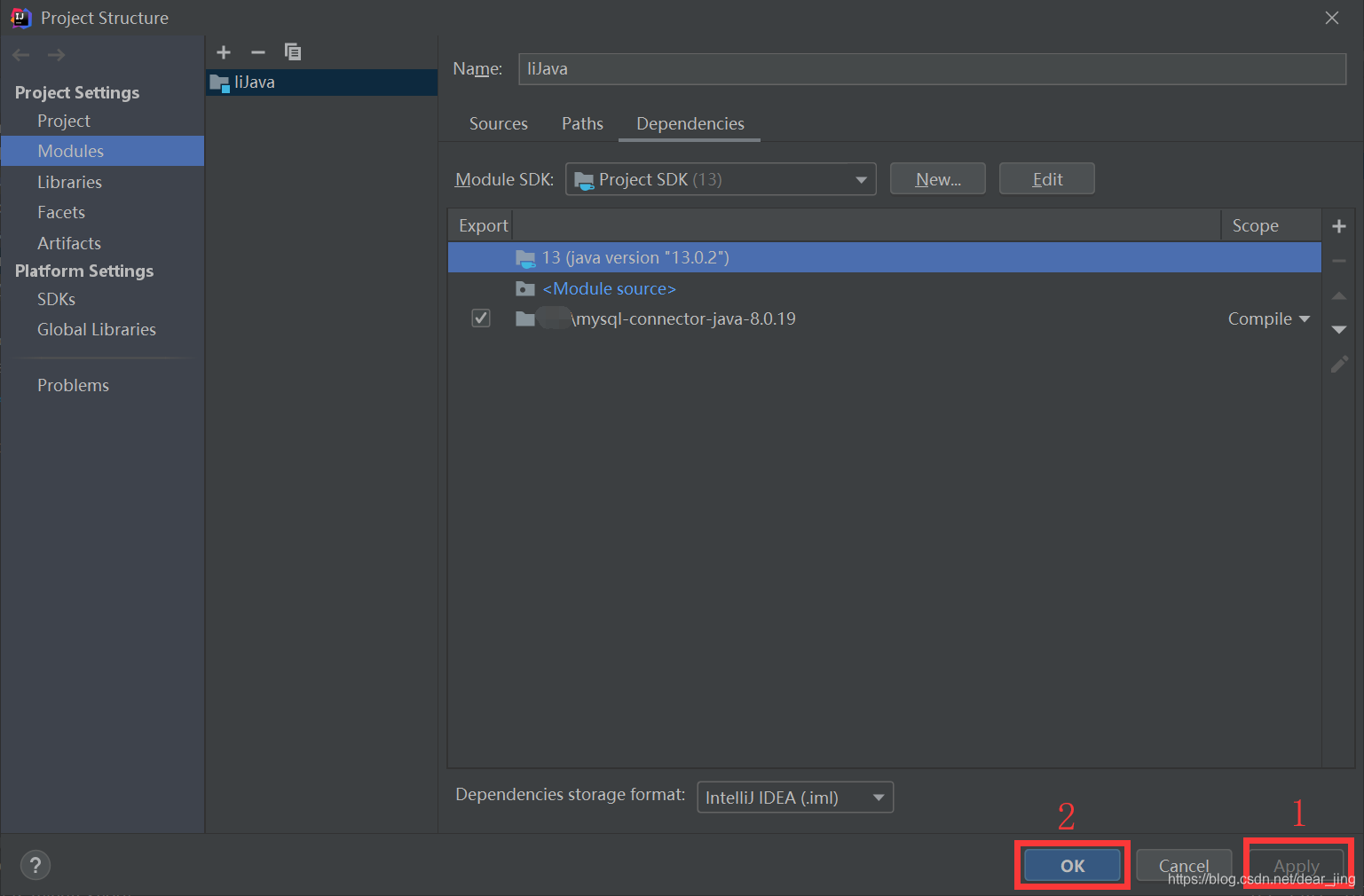
后端需要配置的到此就结束了,让我们写一段代码测试一下吧:
1.建表,给表加上数据:
CREATE TABLE `websites` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` char(20) NOT NULL DEFAULT '' COMMENT '站点名称', `url` varchar(255) NOT NULL DEFAULT '', PRIMARY KEY (`id`));
INSERT INTO `websites`VALUES ('1', 'Google', 'https://www.google.cm/'),('2', '淘宝', 'https://www.taobao.com/'),('3', '微博', 'http://weibo.com/'); 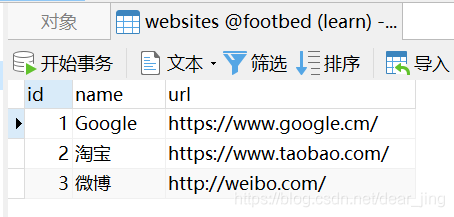
2.Java连接数据库:
注意: 1.JDBC驱动只和数据库有关,因此使用MySQL数据库的驱动为:"com.mysql.cj.jdbc.Driver"。是固定的。 2.数据库URL:"jdbc:mysql://localhost:3306/footbed",footbed需要根据自己的设置,这是数据库名。 3.数据库的用户名USER和密码PASS需要根据自己的设置 package com.jing;import java.sql.*;public class DataClass { // JDBC 驱动名及数据库 URL static final String JDBC_DRIVER = "com.mysql.cj.jdbc.Driver"; static final String DB_URL = "jdbc:mysql://localhost:3306/footbed"; // 数据库的用户名与密码,需要根据自己的设置 static final String USER = "root"; static final String PASS = "xxxx"; public static void main(String[] args) { Connection conn = null; Statement stmt = null; try{ // 注册 JDBC 驱动 Class.forName(JDBC_DRIVER); // 打开链接 System.out.println("连接数据库..."); conn = DriverManager.getConnection(DB_URL,USER,PASS); // 执行查询 stmt = conn.createStatement(); String sql = "SELECT id, name, url FROM websites"; ResultSet rs = stmt.executeQuery(sql); // 展开结果集数据库 while(rs.next()){ // 通过字段检索 int id = rs.getInt("id"); String name = rs.getString("name"); String url = rs.getString("url"); // 输出数据 System.out.print("ID: " + id); System.out.print(", 站点名称: " + name); System.out.print(", 站点 URL: " + url); System.out.print("\n"); } // 完成后关闭 rs.close(); stmt.close(); conn.close(); }catch(SQLException se){ // 处理 JDBC 错误 se.printStackTrace(); }catch(Exception e){ // 处理 Class.forName 错误 e.printStackTrace(); } System.out.println("连接拆除"); }} 
到这就全部结束啦,如有错误之处,还请大家批评指正!!!如果能帮到您,麻烦点个赞~~~ 以上引用了其他博主的文章,如有侵权,会立刻删除。
转载地址:http://eiqqf.baihongyu.com/
你可能感兴趣的文章
实现一个具有Stream的链式、惰性特点的容器
查看>>
Spark源码编译
查看>>
分布式一致性算法(Paxos、Raft、ZAB)
查看>>
MPC多方安全计算——比较算法示意
查看>>
Akka事件驱动——模拟Spark注册、心跳
查看>>
Flink示例——Source
查看>>
Flink示例——Sink
查看>>
Flink示例——Connect、CoMapFunction、Split、Select
查看>>
Flink示例——Window、EventTime、WaterMark
查看>>
Flink示例——State、Checkpoint、Savepoint
查看>>
Flink示例——Table、SQL
查看>>
HBase之Rowkey设计
查看>>
推荐算法——ALS模型算法分析、LFM算法
查看>>
Spark源码剖析——RpcEndpoint、RpcEnv
查看>>
Spark源码剖析——Master、Worker启动流程
查看>>
TensorFlow2 学习——MLP图像分类
查看>>
TensorFlow2 学习——CNN图像分类
查看>>
Spark源码剖析——SparkSubmit提交流程
查看>>
TensorFlow2 学习——RNN生成古诗词
查看>>
Spark源码剖析——SparkContext实例化
查看>>